 首页
首页滚球app网页2026最新版 AI算力“首肯”下, 尼得科在液冷赛谈的“新坐标”

往常两年,要是要找一个在黄仁勋演讲中出现频率越来越高的词,除了GPU,简略等于基础设施。
从AI Factory到GB300,再到下一代AI集群,NVIDIA不绝态状着合并个趋势:算力鸿沟仍在持续扩大。而每一次算力密度晋升的背后,皆伴跟着另一个数字同步增长——功耗。当单机柜功耗向百千瓦迈进,散热运转从数据中心后台的工程问题,变成影响算力部署鸿沟的贫窭变量。
液冷因此走到了产业舞台中央。
围绕液冷张开的新投资、新技俩和新期间不绝涌现,就业器厂商、数据中心运营商、暖通企业和迷惑供应商皆在从头寻找我方的位置。
尼得科亦然其中之一。
不外,与很多从制冷或热看护领域切入液冷的企业不同,这家以电机起家的制造企业看到的,是另一条期间旅途。
“咱们所以电机起家的企业,泵期间才是液冷的贫窭基础之一。”在上海IDCExpo时分,尼得科株式会社微型马达业绩本部本部长,AI & IT业绩部 部长,商品开发第二统括部部长 田中裕司这样诠释谈。

尼得科株式会社微型马达业绩本部本部长,
AI & IT业绩部 部长,商品开发第二统括部部长 田中裕司
这句话背后,其实对应着AI基础设施竖站立在发生的变化。
往常,当液冷还只是少数高密度场景的弃取时,东谈主们更温雅冷板、换热器和散热能力自己。而跟着液冷渐渐走向鸿沟化部署,系统可靠性、历久运行能力以及运维遵循运荡漾得越来越贫窭。
关于领少见千块GPU的AI集群来说,把热量带走只是第一步。真实的挑战在于,奈何让通盘这个词液冷系统在历久运行经过中遥远保持踏实的流量、压力和冷却遵循。
这恰正是泵领悟作用的处所,亦然尼得科最见长的领域。更是尼得科看待液冷市集的起点。
关于一家历久从事电机和泵家具研发制造的企业来说,AI基础设施带来的液冷需求,并非全新的期间命题,而是原有能力在新应用场景下的一次开释。
01 入局液冷赛谈,尼得科的“两张底牌”
关于尼得科而言,液冷并非“从零运转”的跨界。电机、泵、精密制造,以及长达20余年的就业器散热领域教养,这些能力早已存在。跟着AI基础设施全面进入液冷时期,这些能力在合并场景下集会,而集会的第一个载体,正是CDU(冷量分拨单位)。
尼得科的第一张牌,是把“车规级”的泵,放进数据中心。CDU的中枢部件是泵,而泵的本质又离不开马达,这赶巧是尼得科最擅长的领域。
田中裕司显现,尼得科CDU中的中枢泵体,沿用了车载零部件领域积聚的车规级泵期间。
这背后的逻辑在于,汽车历久靠近荡漾、上下温变化以及持续运行等复杂工况,对零部件可靠性和寿命的条款通常高于恒温恒湿的数据中心环境。换句话说,把本来为汽车场景盘算推算的家具应用到机房,自己等于一种“能力降维”,履历过更严苛锻真金不怕火的系统,在相对踏实的环境中通常能够得到更大的可靠性余量。
基于这一想路,尼得科将车规级无密封泵引入CDU,并联结自主开发的电机驱动与泵控期间,构建起液冷系统最中枢的轮回能力。比较单纯采购步伐水泵再进行系统集成,这种决策的上风在于,泵体、驱动和截至系统从底层运转协同盘算推算,能够在历久运行中保持更踏实的流量截至和更高的系统可靠性。
而这种底层可靠性,最终会体面前通盘这个词液冷系统的盘算推算余量上。
以第二代In-Rack CDU为例,其4U机型最高可提供250kW散热能力,单台迷惑即可遮掩一整套NVIDIA HGX B300系统,而GB300机柜本质冷却需求也惟有约144kW。也等于说,在得志面前需求以外,系统仍保留了尽头可不雅的散热空间,以移交翌日硬件升级、负载波动,以及历久运行经过中可能出现的性能衰减。

相通的高可用盘算推算理念也体面前系统架构层面。尼得科在泵体、电源和截至板等要害部件上均选定冗余盘算推算,并援救热插拔珍重,从而在家具架构盘算推算阶段就杀青了“握住机珍重”的看法。
从车规级泵期间到系统级冗余盘算推算,尼得科将汽车产业积聚数十年的可靠性工程教养,迁徙到AI数据中心液冷基础设施之中。
第二张牌是把精密制造教养搬进液冷系统。泵是液冷的腹黑,决定系统能否运转;而快盘问则是命门,它径直决定了机柜里动辄数千万的GPU算力钞票,会不会毁于渗液风险。
其实,液冷大鸿沟部署的除了是散热瓶颈,还有漏液风险。在这一神色,工程容错率趋近于零,一朝快盘问出现问题,冷却链路瘫痪,会将导致底层AI就业器径直燃烧。
尼得科的解法是,哄骗我方最中枢的硬盘马达教养。当作精密制造的“金字塔尖”,硬盘主轴马达对微米级加工、极限密封与洁净度有着严苛条款。尼得科将这套千里淀了数十年的重钞票体系平移,Class 100级无尘车间、油压密封工艺、高精度数控机床,被统共导入快盘问的产线。
终结上,数据也组成了有劲的回话。面前,尼得科UQD和MQD系列快盘问累计出货超 75 万对,于今保持零漏液。
在坐褥上,为了让零漏液的加工精度不出现任何批次过错,尼得科弃取径直管购日本老牌机床企业泷泽(TAKISAWA)。“用我方的车床加工,才敢保证零表现。”田中裕司抒发了尼得科的战术想路。与其满宇宙采购通用迷惑去死磕良率,不如径直把微米级加工的标尺紧紧握在我方手里。
当车规级电机的底座、硬盘产业的精密加工,与自研机床托底的品控体系酿成闭环时,一条高壁垒的护城河就此成型。

02 可堆叠CDU破解制冷“两难”
意会了这些期间积聚,再看尼得科首秀的重磅家具:STC 1.0样机,不觉言之成理。
在液冷领域,数据中心运营商历久靠近两难的形势。一方面,滚球app网页官方版AI芯片迭代太快,今天部署200kW的CDU,来岁新一代GPU上架后制冷能力可能就运转吃紧。然而,要是一步到位上1MW级别迷惑,又容易出现过度建立情况。
STC 1.0惩处的正是这个问题。
STC 1.0给出的想路是把CDU作念成可堆叠的模块化架构。这款CDU妥贴OCP步伐、最多援救5层堆叠的In-Rack CDU。用户不错先部署单层模块得志面前需求,跟着算力鸿沟增长,再缓缓加多新的制冷单位。

“咱们的盘算推算允许客户按热负荷纯真推广。”田中裕司诠释。初期只需运行1层200kW模块,翌日算力扩大,再通过热插拔形状加多第2层、第3层,最高可堆叠至5层,杀青1MW冷却能力。通过定制机架模范,以至能够推广至8层、1.6MW。
每层单位结构孤立,单层故障可单独羁系而不影响其他模块;趋近温度作念到4℃,适配OCP ORV3步伐机架,系统运行时分即可完成CDU单位更换。关于运营商来说,这意味着扩容和珍重皆不消再以停机为代价。
事实上,STC 1.0是尼得科In-Rack阶梯持续演进后的遵循。
往前回看整条家具线,节律其实相配了了。EIA规格的Gen 1.0(200kW,对应NVIDIA HGX B200)、Gen 2.0(250kW,对应B300);OCP规格的Gen 2.5(250kW/160LPM,对应GB300 NVL72,援救51VDC母线输入、兼容NVIDIA MGX);再到Gen 3.0(300kW/280LPM,适配OCP ORV3,援救最新GPU平台);最终发展到可堆叠推广至1MW的STC 1.0。

一代接一代家具升级,对应的是GPU功耗不绝高涨后,液冷系统在制冷能力和流量上的持续晋升。
而当机架功率陆续朝上时,仅靠In-Rack也曾无法遮掩通盘场景,于是尼得科又把能力蔓延到了In-Row家具。
尼得科NIR 2.5和Project Deschutes 5,皆属于2MW级列间CDU。前者达到2MW/2250LPM,后者达到2MW/1890LPM,并也曾通过Google认证。换算到本质部署场景,一台迷惑就足以援救10台NVIDIA NVL72机柜,或者6台下一代超高密度Vera Rubin,NVL72机柜的散热需求。


某种程度上说,这一台CDU也曾能够承担起一个微型AI算力集群的冷却任务。
除了功率鸿沟,两款家具在运维盘算推算上也延续了尼得科一贯的想路。
棋牌牛牛游戏平台APP中国最新版NIR2.5机身高度1.9米,占大地积相对紧凑,可适配集装箱数据中心部署,最多援救10台CDU集群联控,无密封结构泵体援救运行经过中完成滤网清洁和中枢部件热插拔。
Project Deschutes 5则进一步强化了系统踏实性。该家具配备妥贴IEEE 519步伐的ULHD(超低谐波失真)VFD,用于保险供电质料,同期通过0.2μm旁途经滤系统持续守护冷却液洁净度。
03从“随同出海”到押注中国液冷市集
田中裕司展示的一张寰球售后体系舆图,显现出了尼得科在寰球市集的近况。舆图中,蓝色代表也曾参加运营的就业网点,绿色代表斟酌树立中的网点。中国区域面前仍炫夸为绿色。
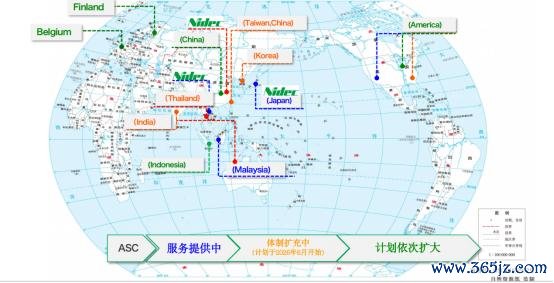
这并不虞味着尼得科缺席中国市集。
事实上,尼得科也曾与不少中国互联网企业和就业器厂商建立联接。只是现阶段,这些联接更多发生在数据中心的出海技俩中。以至,尼得科很早就参与了中国企业的出海进度。
关于液冷行业而言,这样的旅途并不难意会。
数据中心客户采购的除了迷惑自己,还包括备件供应、故障反映、现场珍重,以及历久运维能力。比较也曾建立起纯属就业体系的外洋市集,中国脉土就业麇集的树立赫然还有不少责任要完成。
不外,就业体系仍在树立,并不虞味着尼得科在中国穷乏基础。
依托原有微型马达业务积聚下来的制造能力,尼得科也曾在中国建立了1个期间开发中心(大连期间开发中心)和 3个制造基地(尼得科电机浙江、尼得科电机韶关、尼得科电机东莞)
比较就业麇集,更值得温雅的是尼得科对中国算力市集变化的判断。
往常几年,寰球液冷产业的发展旅途,很大程度上是围绕NVIDIA GPU演进张开的。从H100到B200,再到GB300,就业器架构和散热需求固然持续变化,但举座期间阶梯相对一致。
“而中国市集是另一种情况。”田中裕司如是说
跟着国产GPU缓缓进入查考和推理场景,越来越多原土厂商运转探索新的集群架构。而靠近机柜里面的管路盘算推算、流量分拨、压力截至,以及热门看护的变化,对液冷系统也提议了不同条款。
按照田中裕司的先容,高密度冷板盘算推算和±1℃级别的精确控温能力,皆是围绕高密度GPU集群开发的。当一个节点里堆叠的GPU越来越多,其挑战便不单是产生了些许热量,而是奈何让冷却液均匀流经每一个节点,把热量踏实带走。
关于数据中心运营商来说,散热能力是第沿途门槛,运行资本相通贫窭。
田中裕司提到,往常数据中心的一、二次侧热轮回多半依赖冷水机组,固然能够提供踏实制冷能力,但能耗并不低。跟着液冷缓缓普及,越来越多数据中心运转尝试引入湿热却器等当然冷却决策,但愿进一步降拙劣源破钞。
但当然冷却并不单是把冷水机组换掉这样浮浅。
当外部环境变化更大、系统转化空间变小时,CDU关于流量截至和温度截至的条款反而会进一步提高。换句话说,越想降拙劣耗,越锻真金不怕火液冷系统自己的踏实性。
按照尼得科提供的数据,传统风冷数据中心的PUE频繁在1.6至2.0之间,而液冷决策也曾能够作念到1.1至1.2,举座能耗降幅约为40%。
当AI数据中心运转以数十兆瓦以至上百兆瓦的鸿沟部署时,PUE每下落0.1,最终皆会体面前运营资本上。
除了降拙劣耗,尼得科也在尝试惩处液荒僻地经过中的另一个现实问题:客户奈何考据效果。
田中裕司共享了也曾在日本落地的联接模式。具体来说,技俩由尼得科提供CDU和液冷基础设施,逸想日本提供就业器平台,第三方数据中心运营商MC Digital提供真实机房环境。客户不错径直在本质运行的数据中心里不雅察就业器与液冷系统协同责任的景况,并不单是依赖实验室测试数据。
关于仍处于快速发展阶段的液冷市集来说,这样的考据通常比参数表更有劝服力。
按照尼得科的斟酌滚球app网页2026最新版,访佛联接翌日也将缓缓推广至中国衰退他地区。
 备案号:
备案号: